通过轻量分布式锁解决高并发下数据竞争的一种思路
背景介绍
为了避免数据竞争(Data Race)问题,一般采用加锁的方式对资源的访问进行限制。在单机(单进程)环境中,可以通过编程语言提供的并发控制 API 来实现。然而如今几乎所有大型网站为了解决大流量,高并发的问题,都会选择分布式以及集群部署。在这种情况下,就需要引入分布式锁来实现并发控制。
本文将以笔者在百姓网的经验为例,介绍一种通过轻量级分布式锁解决高并发下的数据竞争问题的思路。
TL;DR
解决数据竞争一般可以采用乐观并发控制和悲并发控制两种方式:
- 悲观并发控制是假设共享的数据很可能被并发地修改,因此一个试图修改数据的程序实例会在对数据进行操作前先加锁,阻止后续的并发修改,直到提交时才释放锁。在这期间其他试图修改该数据的程序实例将阻塞;
- 乐观并发控制假设共享的数据不太可能被并发地修改,因此直接对数据进行操作,当操作结束时检查是否有其他并发的修改在期间被提交,如果有则回滚修改,否则正常提交。
如果对共享数据的操作过程涉及对于外部服务的调用,由于不能确定外部方法的返回时间,采用悲观并发控制可能会导致不可预期的阻塞,极大得影响了并发性能;采用乐观并发控制虽然不会阻塞,但需要考虑如何回滚。大量的回滚同样可能造成性能浪费。
因此,除了尽量减小锁的粒度之外,选择一个合适的并发控制的策略非常重要。
另外,实现锁的方式也有很多种。最简单的是使用RDBMS的事务锁,但缺点是粒度不够灵活;此外也可以基于 Redis 的分布式锁,相比事务锁更加灵活,但需要考虑过期,重复释放等问题。
为了便于理解,下面用一个例子来展示解决数据竞争带来的问题。
一个简单的例子
数据竞争是指存在两个及以上程序实例,它们:
- 试图并发访问同一位置的数据
- 涉及对数据的修改
- 未使用独占锁等访问控制手段^1
设想一个代购服务,用户可以该网站上输入需要购买的商品,后台将订单信息存入数据库,并标记为待购买。同时,后台定时(例如每隔一分钟)获取所有待购买的商品,向经销商发出购买请求,成功后将商品标记为已购买。
假设现在数据库表如下 (foreign_order_id 字段记录了订单在外部系统中的编号,便于后续的追踪):
| id | product | spec | status | foreign_order_id |
|---|---|---|---|---|
| 1 | iPhone X | 土豪金 | PENDING_CREATE | NULL |
| 2 | Bitcoin | 0.001 | PENDING_CREATE | NULL |
| 3 | HEYTEA | 芝士茗茶 | FINISHED | 123456 |
定时任务每分钟扫描这张表。在 t0 发现有 id 为 1 和 2 的状态为 PENDING_CREATE,通过 MQ 发送给 2 个 worker 去执行购买任务 purchase():
1 | def purchase(order_id): |
然而由于队列任务堆积或外部服务不稳定,可能在 t0 + 1min 的时候仍有未完成的任务(状态为 PENDING_CREATE)。此时,定时任务会再次发送相同的购买任务。在这种情况下,如果不加检查可能会出现一个 order 被重复购买的情况。
解决这种问题大概有两种方法:
- 保证相同的任务 被且仅被 发送一次
- 保证任务的 幂等性(即被多次执行不会产生副作用)
第一种解决方案需要保证分布式系统中的强一致性,往往是不切实际的。所以我们把目标放在第二种解决方案上。一个最直观的想法是使用关系型数据库原生的锁。
方案一:使用 RDBMS 的锁
现在修改 purchase() 如下:
1 | def purchase(order_id): |
注意这里引入了事务,并且在一开始获取 order 的时候使用了 FOR UPDATE 为这一行加上了一个独占锁。因此,其他并发的事务对这条记录的更新操作就会被阻塞。这种并发控制也被称为 悲观并发控制,因为它悲观地假设在过程中会出现数据竞争。
悲观并发控制(Pessimistic Concurrency Control)是一种并发控制的方法。它可以阻止一个事务以影响其他用户的方式来修改数据。如果一个事务执行的操作对某行数据应用了锁,那只有当这个事务把锁释放,其他事务才能够执行与该锁冲突的操作。
在效率方面,悲观并发控制的加锁机制会让数据库产生额外的开销,也增加了产生死锁的可能性;同时,一个事务如果锁定了某行数据,其他事务就必须等待该事务处理完才可以处理那行数据,所以降低了并行性。
在我们的假想案例中,我们不能保证外部服务的稳定性,如果 foreign_service.purchase() 这个函数调用会阻塞很久,那么数据库的并发能力便会受到它的影响。
试想这样一种情况:客户希望在购买之后更新他 / 她的订单,而恰好此时该条订单正在被 worker 处理。在这种情况下,由于该订单被加上了独占锁,用户的更新操作会被阻塞,造成用户等待,体验比较差:
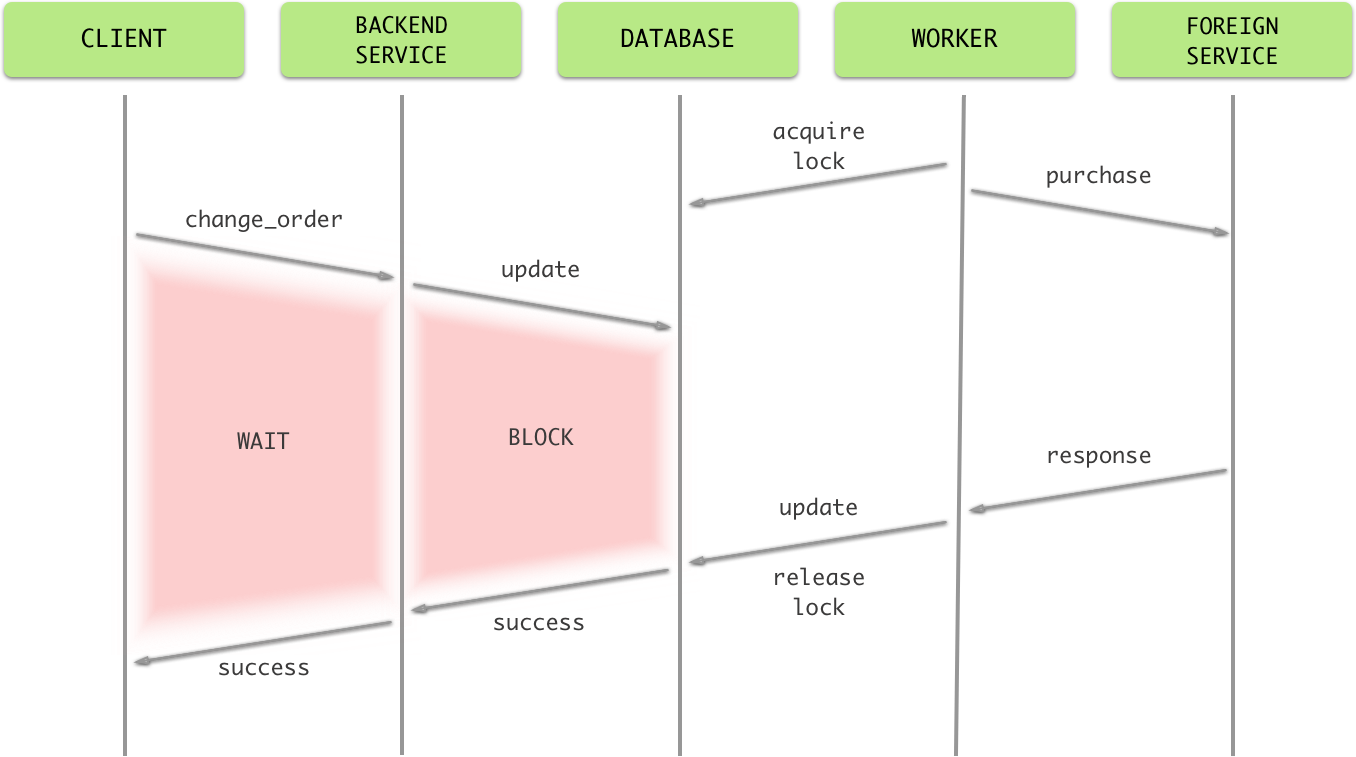 )
)
可能有读者会问,为什么要把耗时的操作放在事务内部,而不在获取外部服务的 response 后再加锁呢?这是由于之前提到并不能保证相同的任务被且仅被发送一次,那么如果有两个 worker 并发执行这个任务就可能出现重复购买的情况。
在实际应用场景中,这种情况并不常见,而我们又必须保证数据的一致性。因此,我们可以采取另一种并发控制的思路:乐观并发控制。它乐观地假定不存在数据竞争的情况,因此尽可能直接做下去,直到提交的时候才去锁定。
乐观并发控制(Optimistic Concurrency Control)是一种并发控制的方法。它假设多用户并发的事务在处理时不会彼此互相影响,各事务能够在不产生锁的情况下处理各自影响的那部分数据。在提交数据更新之前,每个事务会先检查在该事务读取数据后,有没有其他事务又修改了该数据。如果其他事务有更新的话,正在提交的事务会进行回滚。
在效率方面,由于直到提交的时候才会去锁定,所以不会产生死锁。但是如果写操作频率较高,频繁的回滚也会造成无谓的性能浪费。
在我们的案例中,由于 purchase() 涉及外部服务,为了能够回滚需要手动实现对应的 undo 方法。
设想这样一种情况,如果在 worker 接到任务时 id 为 1 的订单为 (1, 1, iPhone X, 土豪金, PENDING_CREATE, NULL),但是等到它提交时,发现该订单已经被更新为 (1, 1, iPhone X, 土豪金, FINISHED,’66666’),它就需要执行与 purchase() 相对应的 undo 方法 cancel_purchase() 。
1 | def cancel_purchase(foreign_order_id): |
但是在某些极端情况下,外部服务可能在此时挂掉,导致 cancel_purchase() 无法执行成功。为了保证数据的最终一致性,需要将这些需要 undo 的信息持久化下来。但这无疑增加了系统的复杂性。
方案二:基于 Redis 的分布式锁
经过上面的尝试,我们发现我们需要的锁最好能够:
- 保证不会有两个并发的 worker 同时处理一条订单(即临界区可以覆盖整个
purchase()过程) - 不会让用户在更新某条订单时被阻塞(不阻塞其它并发修改)
因此,实际上我们需要的是结合悲观锁与乐观锁的一种并发控制方式:悲观锁负责防止并发的 worker 访问,乐观锁能够保证用户的更新不阻塞。显然,数据库的锁不能满足这一要求。因此,我们需要的是一个不依赖于数据库的分布式锁。
分布式锁是一种非常实用的基元 (primitive) ,它能够保证不同程序实例能够以独占的形式操作共享资源。^2
实现分布式锁的方法有很多种,其中比较常见的有:
- 基于数据库(通过插入或删除记录实现加锁)
- 基于分布式协调系统
其中 Zookeeper 是分布式协调系统的一个代表。基于分布式协调系统的锁虽然功能更加健全,但是对于这个案例来说算是大材小用,而且相比基于数据库的并不会带来什么性能优势,所以我们选择了第一种方案。而相比传统的关系型数据库,Redis 不仅并发性能更好,而且自带了具有原子性的 test_and_set 方法 setnx 和过期 (expire) 功能,所以更适合用来实现分布式锁。
一个简单的锁可以如此实现:
1 | def lock(key): |
实际上,redis-py 中已经包含了通过 Lua 脚本实现的与锁相关的 API: Lualock。具体代码^3大家可以自行查看,这里简要介绍一下思路:
- 获取锁:需要传入锁名和一个客户端随机生成的
token,通过setnx插入一条 key 为锁名,value 为token的记录 - 释放锁:需要传入锁名和申请锁时生成的
token,通过 Lua 脚本原子性地:- 检查客户端传入的 key 与
token是否相符 - 相符则删除这条锁的记录,返回成功,否则返回失败
- 检查客户端传入的 key 与
由于 Redis 使用单个 Lua 解释器运行所有脚本,它的原子性是得到保证的:当某个脚本正在运行的时候,不会有其他脚本或 Redis 命令被执行。换句话说,在其他客户端看来,脚本的效果要么是不可见的,要么是已完成的。
可能有细心的读者可能会问 token 的作用是什么。其实它是为了防止一个程序实例释放不属于它自己的锁。如果一个程序实例 A 在获取锁之后被阻塞,在这期间它的锁过期了,而第二个程序实例 B 获取了这把锁。当 A 从阻塞中回复后会尝试释放锁。如果不加判断进行释放就会造成 A 释放 B 新获取的锁,破坏了锁的排他性。所以,获取锁的程序实例需要生成一个唯一的 token 在获取时作为参数传入,并在释放时使用 token 供校验用。
接下来的问题就是确定锁的名称(key)。一个简单的方法是拼接表名,id 和字段名,例如:tb_order:1:status,即锁住 tb_order 表中 id 为 1 的记录的 status 字段。
具体实现大致如下(通过 contextmanager 可以实现在进入 with 语句块时获取锁,在退出时释放锁):
1 |
|
这样就保证了只有一个程序实例可以拿到某条订单记录的独占锁,完成操作后释放,其他并行的程序实例会在其完成前阻塞,等到它们获取锁,检查发现订单状态改变,便直接返回。
但是这也并不能保证万无一失。细心的读者可能会问:如果在 purchase() 执行的过程中用户修改了订单内容怎么办?在这里,我们可以使用类似乐观并发控制的机制。在更新订单状态前检查在过程中订单信息是否被修改:
- 如果未被修改,否则订单状态由待创建 (
PENDING_CREATE) 置为已完成 (FINISHED) - 否则,将订单状态由待创建 (
PENDING_CREATE) 置为待更新 (PENDING_UPDATE) ,并发送异步任务通知 worker 进行更新
无论怎样,在完成上述步骤之后 worker 都会释放锁。更新订单的逻辑与创建订单类似,同样的在提交前也要检查期间订单是否被更改,这里就不赘述了。
具体流程见下图:
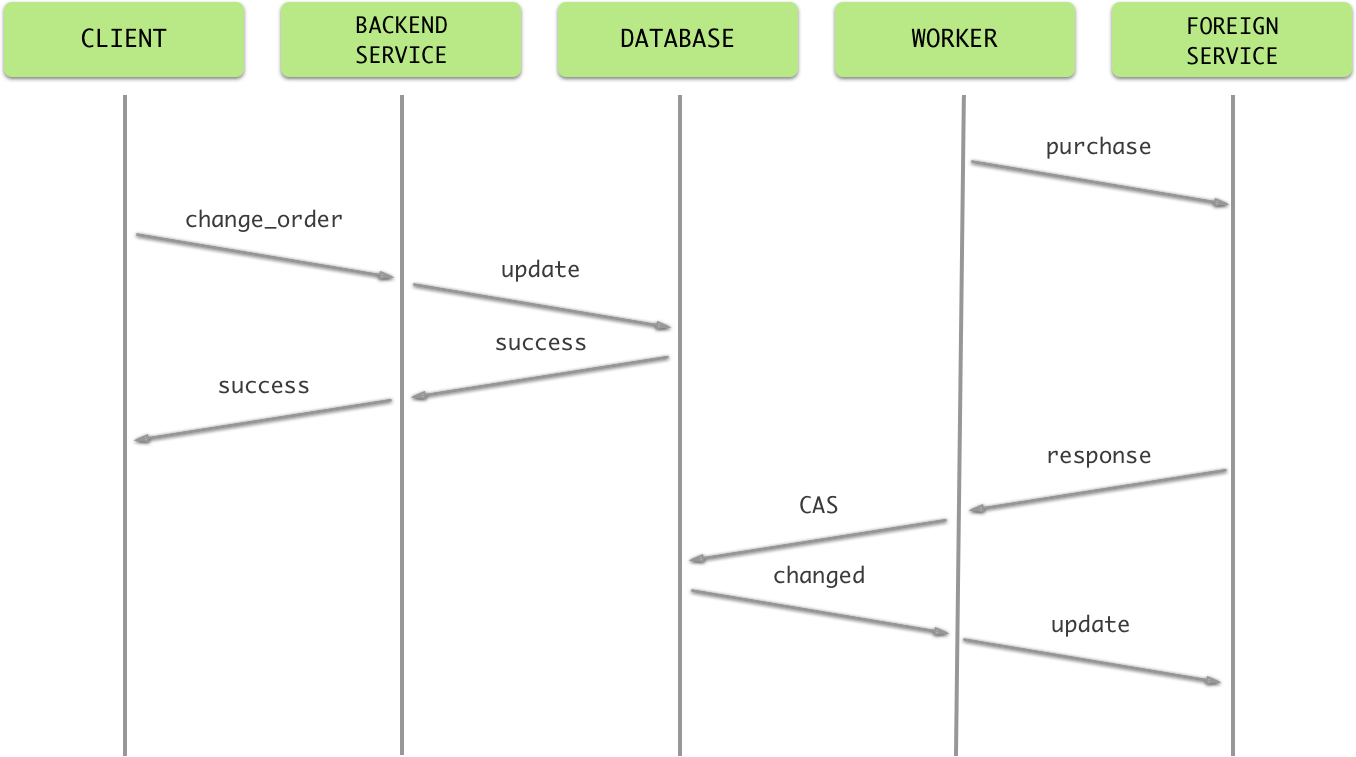
总结
本文介绍了两种并发控制的方式:悲观并发控制和乐观并发控制,并介绍了如何使用 Redis 实现比 RDBMS 原生锁粒度更小的锁来提高并发性能。实际上,不同的并发控制策略并没有优劣之分:在写并不频繁的情况下,使用悲观并发控制将带来并发性能的下降;类似的,在写非常频繁的情况下,使用乐观并发控制也会造成大量的回滚影响性能。因此,应视具体的使用场景灵活地选择并发控制的策略。